Merry X-Mas! Der Splitblog im Dezember
Was wäre der Dezember ohne blankpolierte Jahresrückblicke und Weihnachtsgrüße? Da machen wir natürlich mit. Denn ja: wir alle können auf abgedroschene Phrasen und ach so verherrlichende Beschreibungen verzichten. Was aber wichtig ist, ist auch gelegentlich zurückzublicken und dafür ist der Dezember nun einmal prädestiniert. Also los.
In einem Startup zu arbeiten, fühlt sich manchmal an, wie nach den Sternen zu greifen. Man streckt sich, höher und höher, strengt sich an um noch ein kleines Stückchen weiter zu kommen und am Ende reicht es doch nicht. Wieder einmal. Und was macht man dann? Tief durchatmen, Kräfte sammeln und es noch einmal versuchen. Unterstützung ist enorm wichtig dabei.
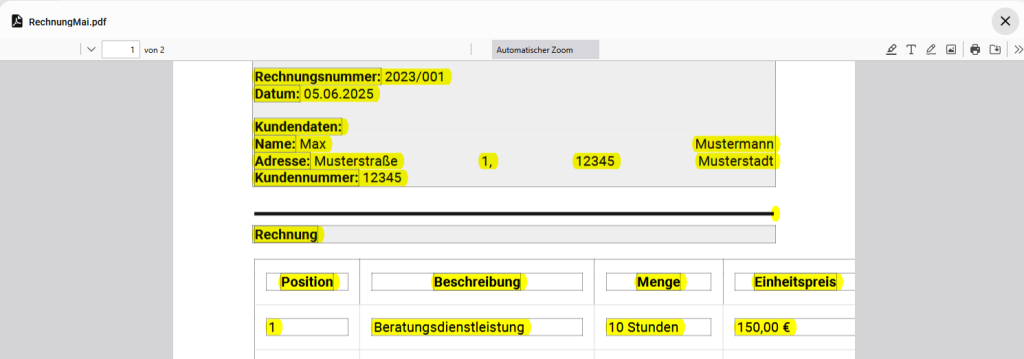
Über eine solche konnten wir uns Anfang des Jahres freuen, als unser eingereichtes Projekt „Chatbot trifft Verwaltung: Intelligente Dialogsysteme als Zukunftslösung für gemeinnützige Organisationen“ im Rahmen der Civic Innovation Platform durch das Bundesministerium für Arbeit und Soziales bewilligt wurde. Gemeinsam mit der Kinderschutzbund Kreisverband Ostholstein e.V., dem Landesverband der Kleingartenvereine Schleswig-Holsteins e.V., InMotion e.V. und dem Ostsee-Holstein-Tourismus e.V. arbeiten wir an EVA – einem KI gestütztem Chatbot, der die Vereinsarbeit erleichtern soll. Inzwischen ist EVA testreif und als open source Software verfügbar. Diese Kooperation hilft uns, bei der Entwicklung ein breites Spektrum an Bedarfen zu berücksichtigen. Wir sind sehr dankbar für die von den beteiligten Vereinen investierte Zeit, den positiven Austausch und das Feedback. Auch die unkomplizierte Hilfe unserer externen Berater vom Zukunftslabor Generative KI, von DSS IT Security und der Kanzlei Lauprecht ist Gold wert.
Einige wichtige Vertragsabschlüsse sind uns in diesem Jahr ebenfalls gelungen, die uns gezeigt haben, dass wir auf dem richtigen Weg sind und mit unserer Idee einen realen Bedarf decken.
Was auch hilft: Anerkennung. Und auch die wurde uns in diesem Jahr im Form des 1. Platzes des Digitalisierungspreises Schleswig-Holstein, persönlich überreicht von Dirk Schrödter. So eine Trophäe sieht nicht nur hübsch aus, wenn sie beleuchtet im Meetingraum steht, sondern hat auch eine unheimliche Symbolkraft. Ein „Mutmachpreis“, wie Herr Schrödter treffend formulierte. Denn genau das ist es, was den Unterschied machen kann: Der Mut es weiter zu versuchen.
Wir haben als Team in diesem Jahr einiges auf die Beine gestellt und sind an manche Stellen noch enger zusammengerückt. Denn wenn man Rückschläge gemeinsam aushält, machen die Erfolge umso mehr Spaß. Jede und jeder von uns ist in den letzten Monaten mehr als nur eine Extrameile gelaufen. Stellvertretend dafür soll hier einer genannt sein: Unser Auszubildender Ramtin. Ramtin, den man niemals erst bitten muss und dessen Engagement weit über das Standardmaß hinausgeht. So ist es auch kaum verwunderlich, dass er sich schon weit vor Ende der Ausbildungszeit über einen unbefristeten Vertrag freuen darf.
Der Web Summit in Lissabon, an dem wir als Teil der de:hub Initiative teilnehmen durften, war ebenfalls ein inspirierendes Ereignis. Wer schon einmal dabei war, wird diese beeindruckende Atmosphäre und den Spirit kennen.
Und dann ist da noch Friedrich, der uns und die Kontor Business IT schon seit den Anfängen nicht nur begleitet, sondern nach Leibeskräften unterstützt. Der in diesem Jahr seinen Masterabschluss gemacht und nun gemeinsam mit Tadeusz die Splitbot führt.
Tja, und nun? In Händen halten wir ihn wohl noch nicht, unseren Stern. Aber er ist in Reichweite. Und wir werden auch im nächsten Jahr alles daran setzen, ihn zu erreichen. Das Ziel vor Augen und unser Netzwerk und unser Team im Rücken.